La inteligencia artificial sigue avanzando y creando nuevas aplicaciones. Muchos investigadores comienzan a comprender la utilidad de las redes neuronales, un área de la Inteligencia Artificial que aún está en desarrollo. Recientemente, un equipo de investigación de la Universidad de Zhejiang y Fuxi AI Lab de NetEase, ha desarrollado un sistema muy interesante que permite generar una animación facial a partir de una pista de audio. Su innovación se llama Audio2Face y podría ser muy útil para los profesionales de la animación.
Hace unas semanas, Google reveló una red neuronal que era capaz de crear un poema desde una cara. PoemPortraits, un proyecto que se inspira en una red neuronal de miles de poemas del siglo XIX, casi 25 millones de palabras para ser precisos. El funcionamiento es muy sencillo, únicamente necesita una palabra cualquiera introducidida por el usuario y la foto del rostro de la personaa, partir de estos dos elementos se crea un poema personalizado. Por extraño que parezca, vale la pena probarlo por unos minutos.
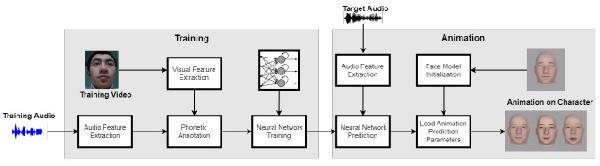
Pero volvamos a Audio2Face, los investigadores han sido capaces de animar una cara desde una pista de audio, explican que: "nuestro enfoque depende exclusivamente de una pista de audio, no hay imágenes en las entradas de información. Por lo tanto, la animación de las caras es bastante difícil de realizar. El otro desafío es que los movimientos faciales implican múltiples activaciones de regiones correlacionadas en la superficie geométrica de una cara. Sin embargo, hemos logrado generar movimientos realistas en nuestros avatares."
Los investigadores han querido a toda costa respetar dos criterios esenciales: sus avatares tenían que mantener cierta vivacidad y adaptarse en tiempo real. En este sentido, el sistema de inteligencia artificial creado por este equipo toma en promedio solo 0,68 milisegundos para extraer los datos de una pista de audio y traducirlos en movimientos. Reconocen que lo más complicado ha sido el parpadeo de los ojos de los avatares. De hecho, este movimiento no depende del habla, por lo que es difícil de comprender para la IA.







